Shapley 値によるモデルの解釈
以前の記事で、ランダムフォレスト(RF)による記述子の特徴量解釈について、少し触れました。
予測に関する記述子の役割をより深く考察するのに、shapley 値を用いた SHAP というものがあります。
Shapley 値はゲーム理論に基づき算出される値で、以下のブログに分かりやすく説明されています。
上のブログの例では、A、B、C の 3 人で力を合わせて 24 万円稼いだ場合、誰がどれくらい稼いだかを限界貢献度を元に表現しています。
A だけだと 6 万円、B だけだと 4 万円しか稼げませんが、A と B の二人だと 20 万円稼げます。ここで、B の仕事を A が手伝う(A が後から来る)とみなすと、A は 16 万円分働いていると考えられます。逆に、A の仕事を B が手伝う(B が後から来る)とみなすと、B は14 万円分働いたことになります。特徴量を追加する順番で稼いだ額、すなわち限界貢献度が異なりますので、順列を考え、全てのパターンの平均値を取ることで、Shapley 値が算出できます。
シンプルに考えるならば、Shapley 値が大きければ、目的変数に大きく寄与している、とみなせます。
SHAP を用いて機械学習モデルを解釈することもできます。
事前準備として、shap をインストールしておきましょう。
pip install shap
以前作成したLogS 予測 RFR モデルとデータを読み込んで、SHAP による解釈を行います。
import numpy as np import pandas as pd from rdkit import Chem from rdkit.Chem.Draw import IPythonConsole import shap import matplotlib.pyplot as plt import pickle # データの読み込み X_train = pd.read_csv("../data/LogS_train_scaled.csv", index_col = 0) X_test = pd.read_csv("../data/LogS_test_scaled.csv", index_col = 0) descriptor_label = X_train.columns y_train = pd.read_csv("../data/LogS_train_value.csv", index_col = 0) y_test = pd.read_csv("../data/LogS_test_value.csv", index_col = 0) # モデルの読み込み loaded_model = pickle.load(open("../model/RFR_LogS.sav", "rb")) # Shapley 値を計算 explainer = shap.TreeExplainer(model = loaded_model) train_explainer = explainer(X_train) test_explainer = explainer(X_test)
TreeExplainer で SHAP を実行するインスタンスを作成し、それにデータセットを入力することで Shaley 値を計算します。
実務上の注意点として、モデルに使用する特徴量の数が多いと SHAP の計算は時間がかかります。今回のモデルの構築には 94 記述子しか使っていないので、普通に計算できますが、数百記述子以上になると計算が中々終わらないので、気をつけて下さい。
train(test)_explainer はデータが格納されているインスタンスなので、色々取り出すことが可能です。例えば、 .values で Shapley 値そのものを取り出すことができます。
私が勉強不足なのでメソッドの詳細な説明は、公式ドキュメントや以下のブログに譲り、本記事では化学データの解釈に的を絞りたいと思います。
算出した Shapley 値を元に、データの解釈をしてみましょう。
まずは、bar plot を表示、出力してみましょう。
# 記述子の Shapley 値の平均値を bar plot として表示。 # 棒グラフに隣接している数値は Shapley 値であり、base value に加える値。 # 左の灰色の数字は元データにおける記述子の値 f = plt.figure(figsize = (8, 8)) shap.plots.bar(train_explainer[0]) # データを出力 f.savefig("../result/barplot_molecule.png", bbox_inches = "tight", dpi = 600)
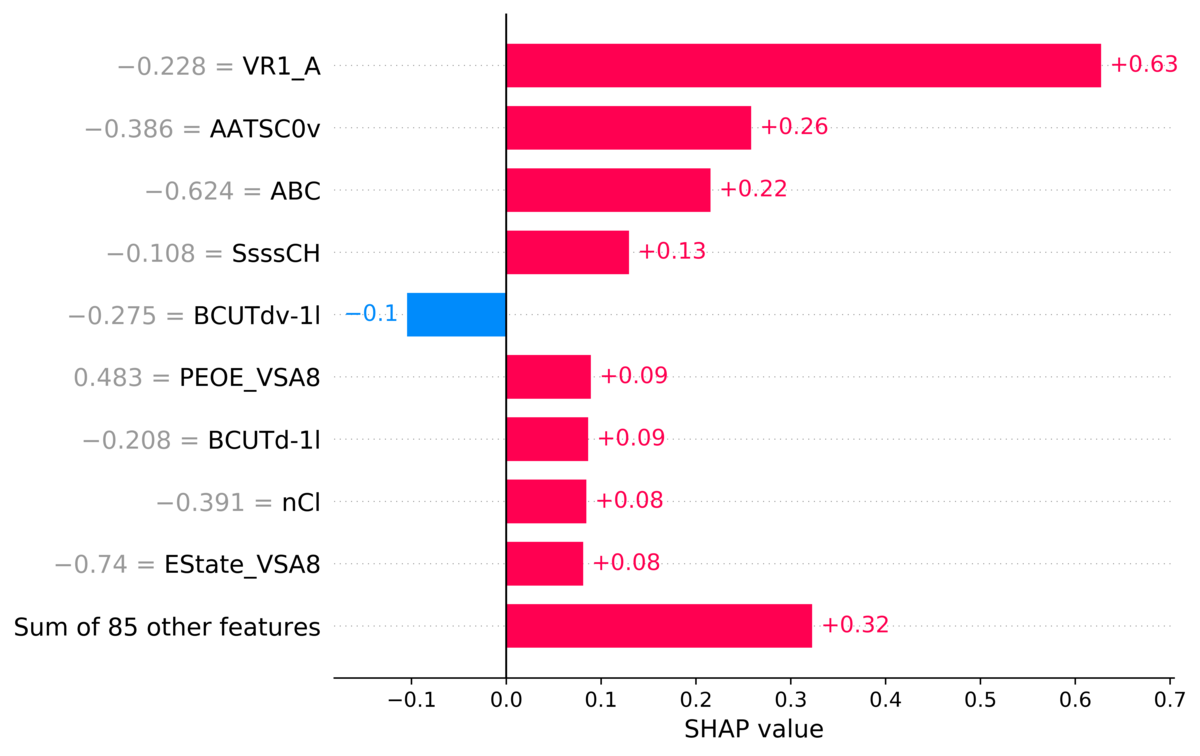
Bar plot では、各記述子についての Shapley 値の絶対値を示しています。Shapley 値はデータごとに計算されるので、feature importance のように、モデル固有の値でない点にも注意して下さい。
バーの真横にある赤 or 青で書かれているのが、あるデータ、記述子に対する Shapley 値です。赤だとプラス、すなわち予測結果の値を大きくするのに寄与し、青だとマイナス、すなわち予測結果の値を小さくするのに寄与します。
Base value が各モデル固有の値として与えられていますが、この Shapley 値を加えていくことで、予測結果が得られます。
ちなみに、左にある灰色の数字は、元の記述子の値です。
summary_plot を使っている記事が多いですが、bar で作ると色々融通が効きそうです。
細かい点を補足すると、explainer のインスタンスに対し、データの番号を指定することで特定のデータに対する bar plot を作れます。また、bar の関数の max_display という引数に数字を入力すると、plot で表示されるバーの本数を調整できます(一本は残りの記述子の Shapley 値を纏めたものになる点に注意)。bbox_inches を "tight" にしないと、プロットが見切れて出力されてしまう点も注意です。
Bar plot はモデル全体についても表示できます。
# モデル全体についての bar plot を表示 # 数字は絶対値の平均を表している点に注意。 f = plt.figure(figsize = (8, 8)) shap.plots.bar(train_explainer, max_display = 30) # データを出力 f.savefig("../result/barplot_whole.png", bbox_inches = "tight", dpi = 600)
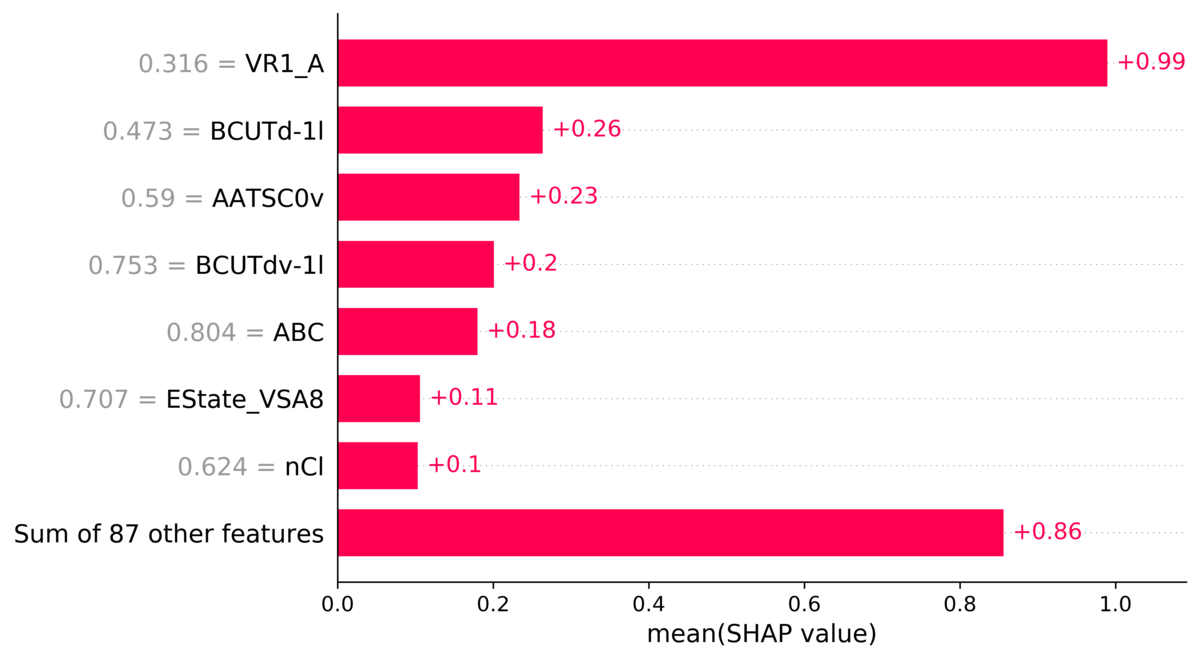
Shapley 値(と記述子の値)は、絶対値をとったものの平均値である点に注意してください。そのため、このプロットでは、値の増減にどう寄与したか判別することはできません。どの記述子が、予測値に大きく寄与したかは言えます。使い方としては、feature_importance に近いです(値や記述子の順番は一致するとは限りません)。
SHAP には他に force plot も用意されており、より視覚的にどの記述子が変化するかが見やすくなります。
# Force plot の表示 # 引数は base value, shapley 値のベクトル、記述子名 f = shap.plots.force(train_explainer.base_values[0], train_explainer.values[0], train_explainer.feature_names, matplotlib = True, show = False) # データを出力 f.savefig("../result/forceplot_molecule.png", dpi = 600)
Force plot も、全データを一度に表示させる機能はあるのですが、正直、あまり見やすいとは思わないので、説明は割愛します。
(他のプロットについては追記予定です)