小ネタ:ランダムフォレストの実装 + モデルの保存方法 + プロット作成の基本
ケモインフォマティクスでは回帰問題、あるいは判別問題をよく扱います。様々な機械学習モデルがあると思いますが、最も使いやすいモデルとして、ランダムフォレスト(RF)があります。RF の数学的原理を解説しているサイトは多数あるので、ここでは触れません。
RF を使う実務上のメリットとして、以下の点が挙げられます。
・特徴量の前処理をしなくても良好なモデルが得やすい。
・どのような特徴量が予測に有用なのか、寄与率(feature importance)を基に考察ができる。
・パラメーターチューニングをそこまでしなくても良好なモデルが得やすい(n_estimator (木の本数)を取り敢えず増やしておけば良い)。
・並列化が用意(n_jpbs という引数がある)
・データセットのサイズが小さくてもモデルが組める。データサイズが数千ぐらいだと、gradient boosting より性能が良いこともしばしば。
外挿に弱いなどの欠点もありますが、基本的には初心者でも扱いやすく、かつ良い結果が出やすいので、個人的には非常にオススメする手法です。
何かデータがあったときは、取り敢えず RF を試してみると良いと思います。
以下、モデルの解釈、保存まで含めた実装例です。
import numpy as np import pandas as pd from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import r2_score, mean_squared_error import matplotlib.pyplot as plt import pickle # データの読み込み X_train = pd.read_csv("../data/LogS_train_scaled.csv", index_col = 0) X_test = pd.read_csv("../data/LogS_test_scaled.csv", index_col = 0) # 記述子名のリストを取り出す descriptor_label = X_train.columns y_train = pd.read_csv("../data/LogS_train_value.csv", index_col = 0) y_test = pd.read_csv("../data/LogS_test_value.csv", index_col = 0) # モデルの構築 rgr = RandomForestRegressor(random_state = 0) rgr.fit(X_train, y_train) y_pred = rgr.predict(X_test) # R2 値を表示 print("R2:") print(r2_score(y_test, y_pred)) print("-----\n") # 平均二乗誤差(RMSE)を表示 print("RMSE:") print(mean_squared_error(y_test, y_pred)) # モデルを保存 pickle.dump(rgr, open("../model/RFR_LogS.sav", "wb"))
今回のデータは、こちらのコードで作成したものを読み込んでいます。
データを読み込んだ時点では pandas の dataframe の形式になっているので、columns で記述子名を取り出します。これは、記述子の寄与率解釈の時に使います。
RF の実装は 3 行で出来てしまいます。最初にインスタンスを作成し、fit で学習データを入力、predict で予測ができます。前処理がいらないので、これでモデルの完成です。木の本数を増やしたいときは、最初のインスタンス作成の時点で n_estimators に数字を指定すれば良いです。取り敢えず大きい数にすれば予測性能は上がりますが、一定の数で頭打ちになるのと、本数が多いと計算時間がかかるので、マシンスペックと相談して決めると良いです。
ちなみに、判別モデルのときは、あるクラスに分類されると予測した木の本数の割合を、そのクラスに分類される確率とみなすことができます。この確率は、predict の代わりに predict_proba を指定することで算出することができます。
R2 と RMSE の表示もしてみます。R2 の説明は、上に出した記事に書いてあるので、省略します。RMSE は、どれくらい予測結果に誤差があるかを示す指標です。負ではない値を取り、0 に近い程、誤差が小さいので良好な予測が出来ていると解釈します。扱うデータや他のモデルとの比較によって、数字の良し悪しが変わるので、絶対値だけで解釈しないよう、注意が必要です。
モデルの保存は pickle.dump を使います。モデルを書き込むので、 open の引数に "wb" を指定します。覚えていれば一瞬なのですが、書く時に忘れがちなので、自分のメモとして記載しておきます。
モデルを保存したら、読み込みたい場面も出てきます。pickle.load で作成した機械学習モデルを読み込めます。気になる人は、以下のコードを試してみて、ちゃんと結果が再現できるか試してみて下さい。
# モデルの読み込み loaded_model = pickle.load(open("../model/RFR_LogS.sav", "rb")) # 予測結果が同じか確認 y_loaded_pred = loaded_model.predict(X_test) # R2 値を表示 print("R2:") print(r2_score(y_test, y_loaded_pred)) print("-----\n") # 平均二乗誤差(RMSE)を表示 print("RMSE:") print(mean_squared_error(y_test, y_loaded_pred))
寄与率を基に、どのような記述子が予測に有用か、確認をしてみましょう。
# 寄与率が高い特徴量を表示 feature_importances_top_indices = np.argsort(loaded_model.feature_importances_)[::-1][:15] for i in feature_importances_top_indices: print(descriptor_label[i]) print(loaded_model.feature_importances_[i]) print("----------\n")
RF モデルのインスタンスに feature_importances_ とあるので、これで記述子の特徴量を表示出来ます。ただし、学習に用いた記述子の順番通りに並んでおり、どの記述子が一番重要なのか分かりにくいです。そこで、記述子の大きい順に並び替えをしてあげて、上位何種類か(今回は 15 種類)をインデックスとして取得します。このインデックスを基に、特徴量の大きい順に値と記述子名を表示していきます(ここで最初に取得した記述子ラベルを使います)。
最後に、実測値と予測値がどの程度一致しているか、y-y plot を基に確認してみましょう。y-y plot は、実測値と予測値を二次元上にプロットした図であり、対角線(実測値と予測値が一致)に近い程良いと解釈する図です。Python だと、matplotlib を使うと綺麗な図が書けるのですが、少し扱いが難しいです。y-y plot 作成コードの例は以下の通りです。
# y-y plot を作成 # フォントを変更 plt.rcParams["font.family"] = "Arial" # Plot のインスタンスと図の大きさを定義 fig = plt.figure(figsize = (10, 10)) # インスタンスの中に複数のグラフを作る場合に指定 # 引数は(行数、列数、具体的に作りたい図のインデックス) # グラフを 1 つだけ作りたいときは (1, 1, 1)としてやれば良い ax = fig.add_subplot(1, 1, 1) # グラフのタイトル ax.set_title("y-y plot", fontsize = 28) # グラフの表示範囲 ax.set_xlim(-9, 2) ax.set_ylim(-9, 2) # 目盛の数字の大きさを調整 ax.tick_params(axis = "x", labelsize = 16) ax.tick_params(axis = "y", labelsize = 16) # 軸の名称を指定 ax.set_xlabel("True_LogS", fontsize = 20) ax.set_ylabel("Pred_LogS", fontsize = 20) # 対角線(y = x)を引く ax.plot(list(range(-9, 3)), list(range(-9, 3)), "k") # データをプロットする ax.scatter(y_test, y_loaded_pred, c = "dodgerblue") # 図を保存 fig.savefig("../result/y_y_plot.png")
最初に、図のフォントを指定します。細かい設定をするには他の操作が必要だと思いますが、今回は取り敢えず arial で統一してしまいます。次に、figure のインスタンスを作成します。ここで、図全体の大きさをインチ単位で指定します。そして、add_subplot で図のどこにグラフ (axes) を作成するか指定します。ここが分かりにくいのですが、figure で図全体を作成し、そこに各グラフ(axes インスタンス)を放り込んで細かく作っていく、というのが大雑把なイメージだと思います。また、matplotlib で図の作り方を調べると、plt に色々追加していくやり方も多く見られますが、図を細かく指定するには、axes インスタンスに対し操作をしていくやり方に慣れておいた方が良いと思います。Subplot を使って複数の図を作る事例が多く紹介されていますが、最初は一つの図だけを作る場面の方が多いと思うので、add_subplot は(1, 1, 1) で良いです。
グラフの表示範囲は、必ず全てのデータが範囲内に含まれているか確認して下さい。範囲外にデータがあると、プロットされません。
plot で線を、scatter で点を描くことができます。
プロットの色は、簡単な色であれば、一文字で表現できます ex) "k": 黒
また、以下の表にある色は文字で指定できます。
作成したプロットは、こんな感じです。
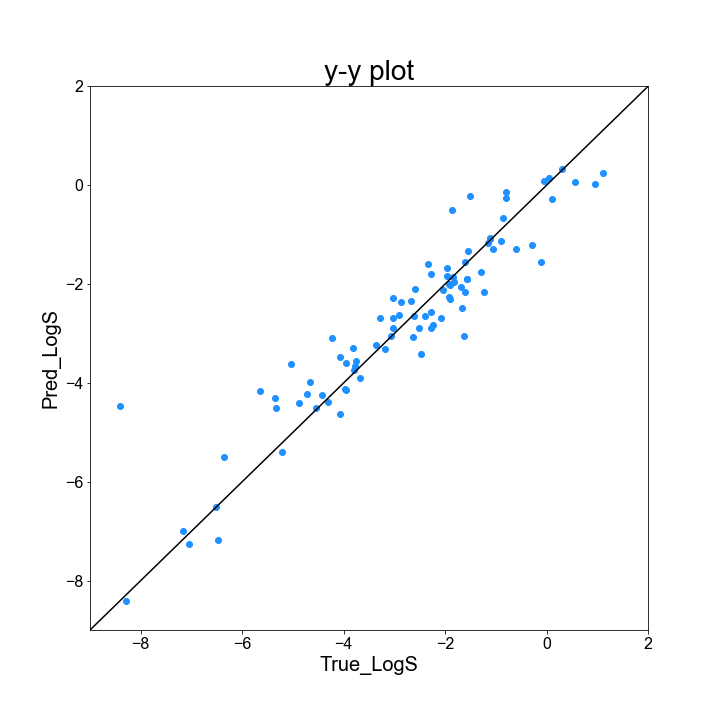
対角線の左上にあると、実測値よりも大きく、右下にあると実測値よりも小さく LogS を予測したことになります。